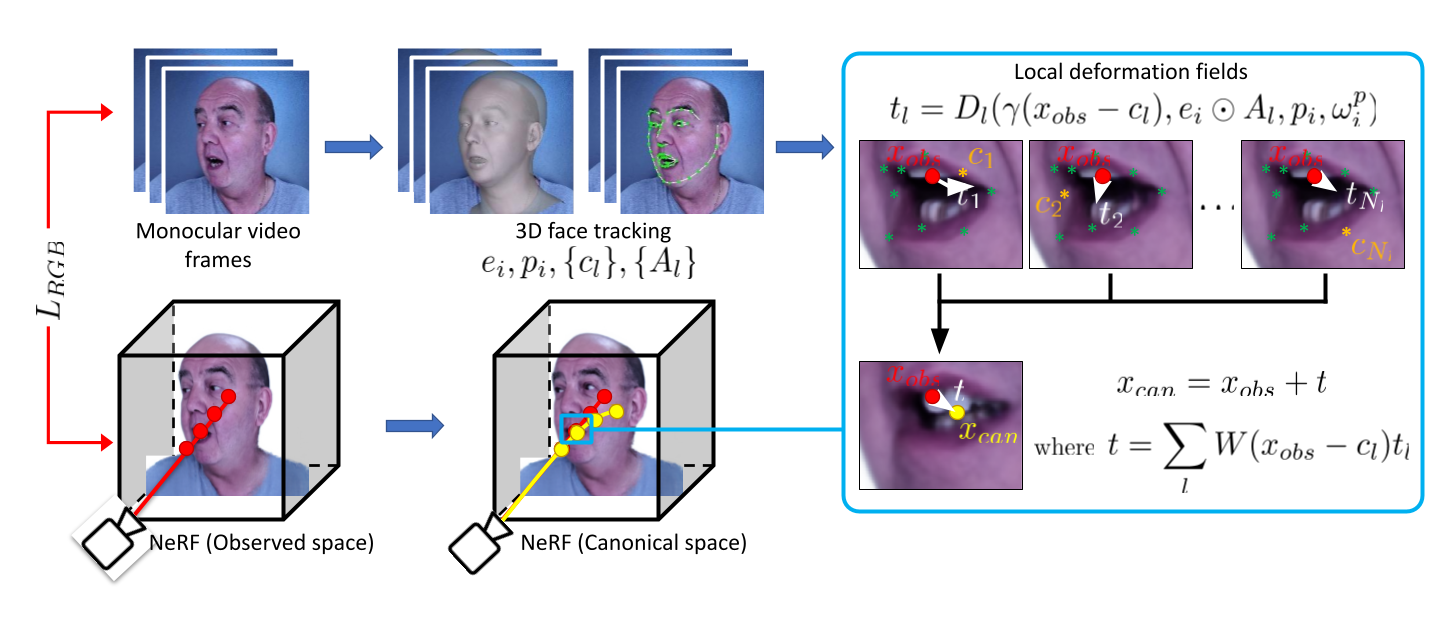
Given an input video sequence, we run a face tracker to get at each frame the following parameters
of a linear 3DMM: expression code, pose code, and sparse 3D facial landmarks. An attention mask with local spatial support is
also pre-computed from the 3DMM. We model dynamic deformations as a translation of each observed point to the canonical
space. We decompose the global deformation field into multiple local fields, each centered around
representative landmarks. We enforce sparsity of each field via an attention mask that modulates expression code. Our
implicit representation is learned using RGB information, geometric regularization and priors, and a novel local control loss.
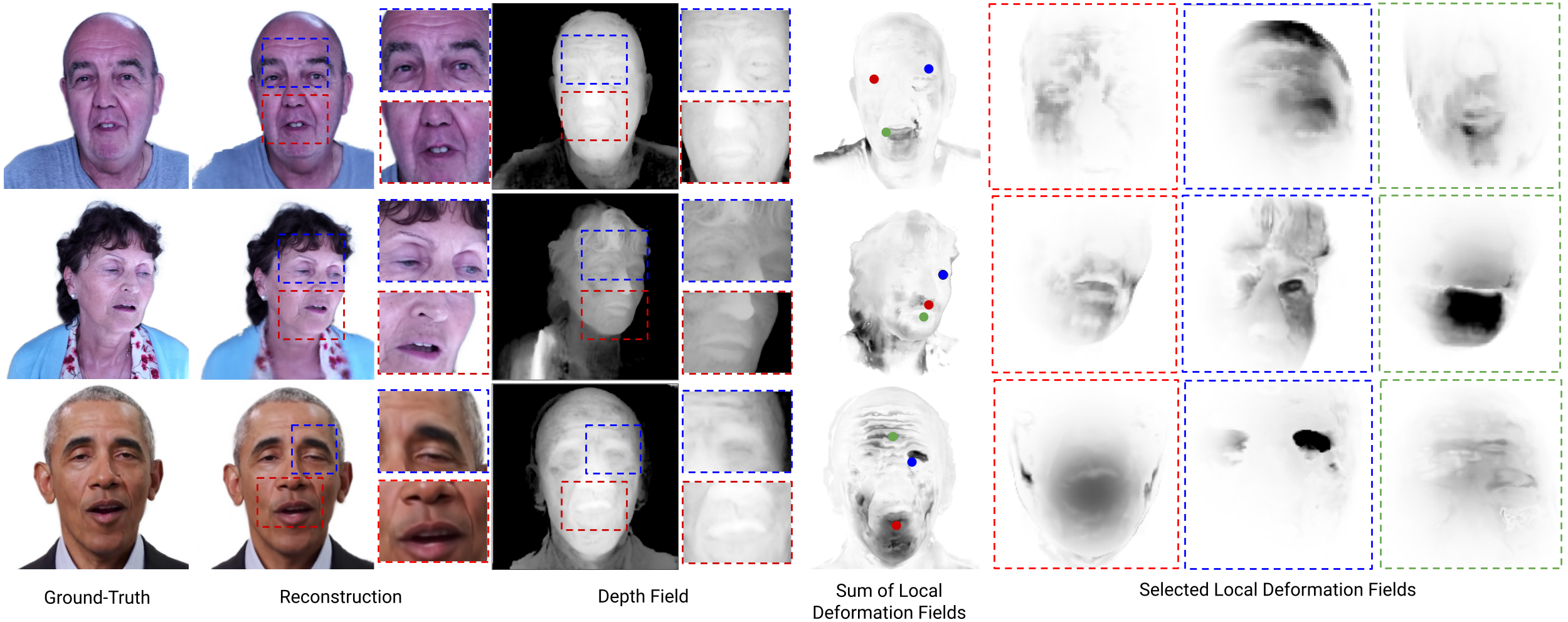
Our approach is able to reconstruct test images to great detail with accurate geometry. The facial deformation caused by expressions are decomposed into local deformations, shown in the following visualization.
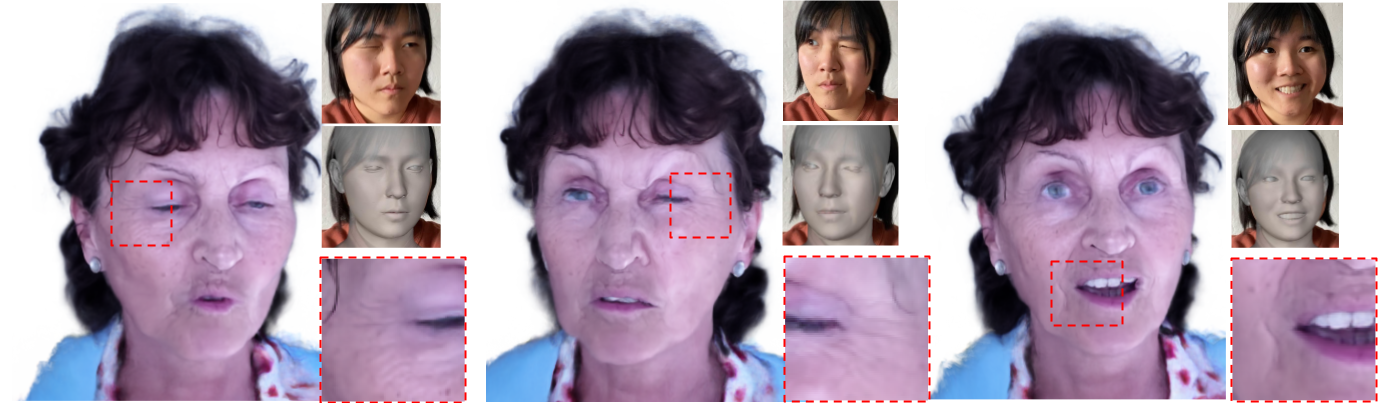
We model user's expressions (top) via DECA and transfer the 3DMM parameters (middle) to the neural head model of the subject. The model produces asymmetric expressions under the user's pose with a
high level of details (bottom) that surpasses the linear 3DMM. Note that none of the transferred expressions were in the training set.
-->
@inproceedings{chen2023-implicit_head,
title={Implicit Neural Head Synthesis via Controllable Local Deformation Fields,
author={Chen, Chuhan and O'Toole, Matthew and Bharaj, Gaurav and Garrido, Pablo},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2023}
}