
Scene 001

Scene 002

Scene 003

Scene 004

Scene 005

Scene 006

Scene 007

Scene 008

Scene 009

Scene 010

Scene 011

Scene 012

Scene 013

Scene 014

Scene 015

Scene 016

Scene 017
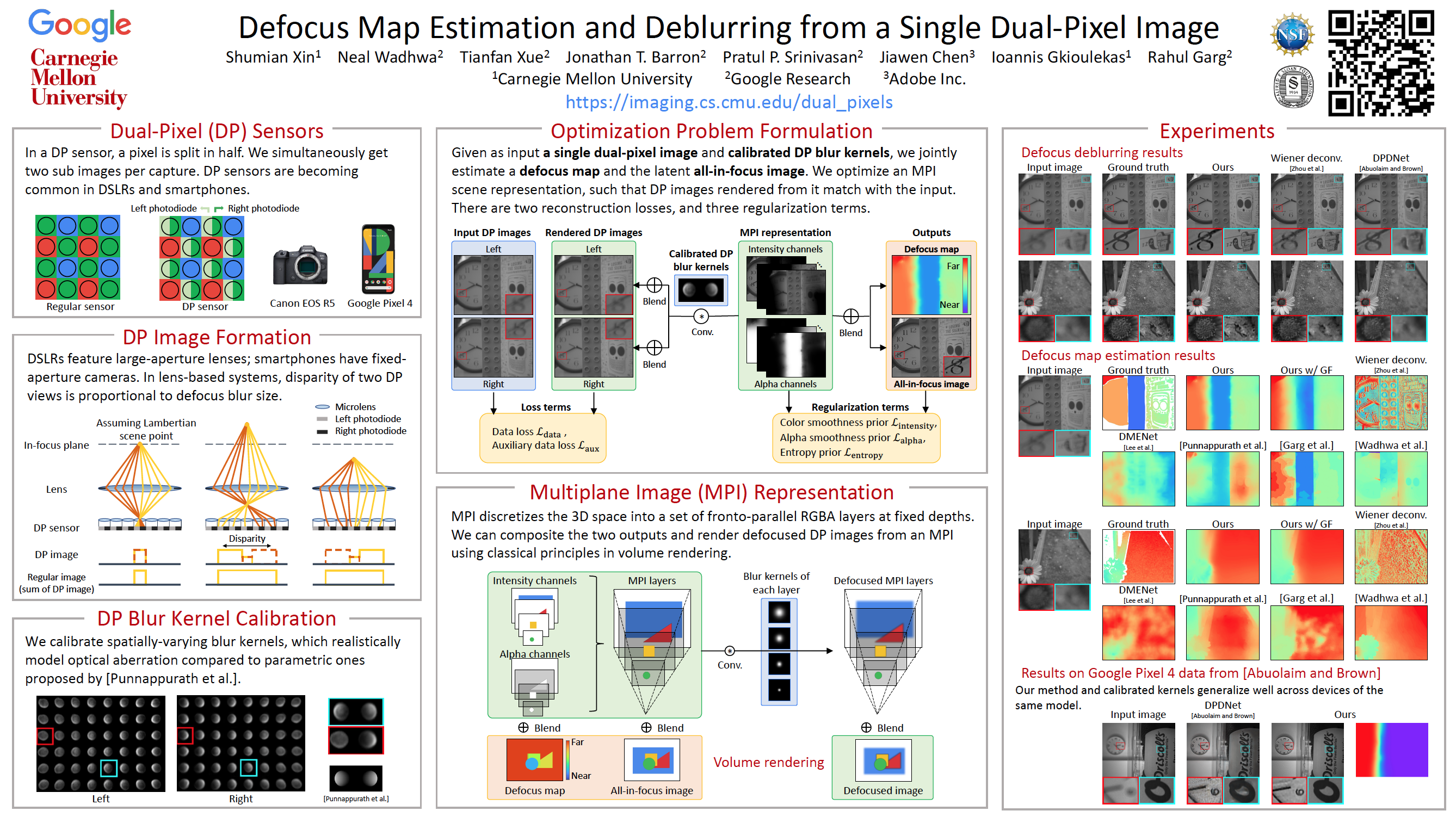
We present a method that takes as input a single dual-pixel image, and simultaneously estimates the image’s defocus map—the amount of defocus blur at each pixel—and recovers an all-in-focus image. Our method is inspired from recent works that leverage the dual-pixel sensors available in many consumer cameras to assist with autofocus, and use them for recovery of defocus maps or all-in-focus images. These prior works have solved the two recovery problems independently of each other, and often require large labeled datasets for supervised training. By contrast, we show that it is beneficial to treat these two closely-connected problems simultaneously, and we set up an optimization problem that, by carefully modeling the optics of dual-pixel images, jointly solves both problems. We use data captured with a consumer smartphone camera to demonstrate that, after a one-time calibration step, our approach improves upon prior works for both defocus map estimation and blur re-moval, despite being entirely unsupervised.

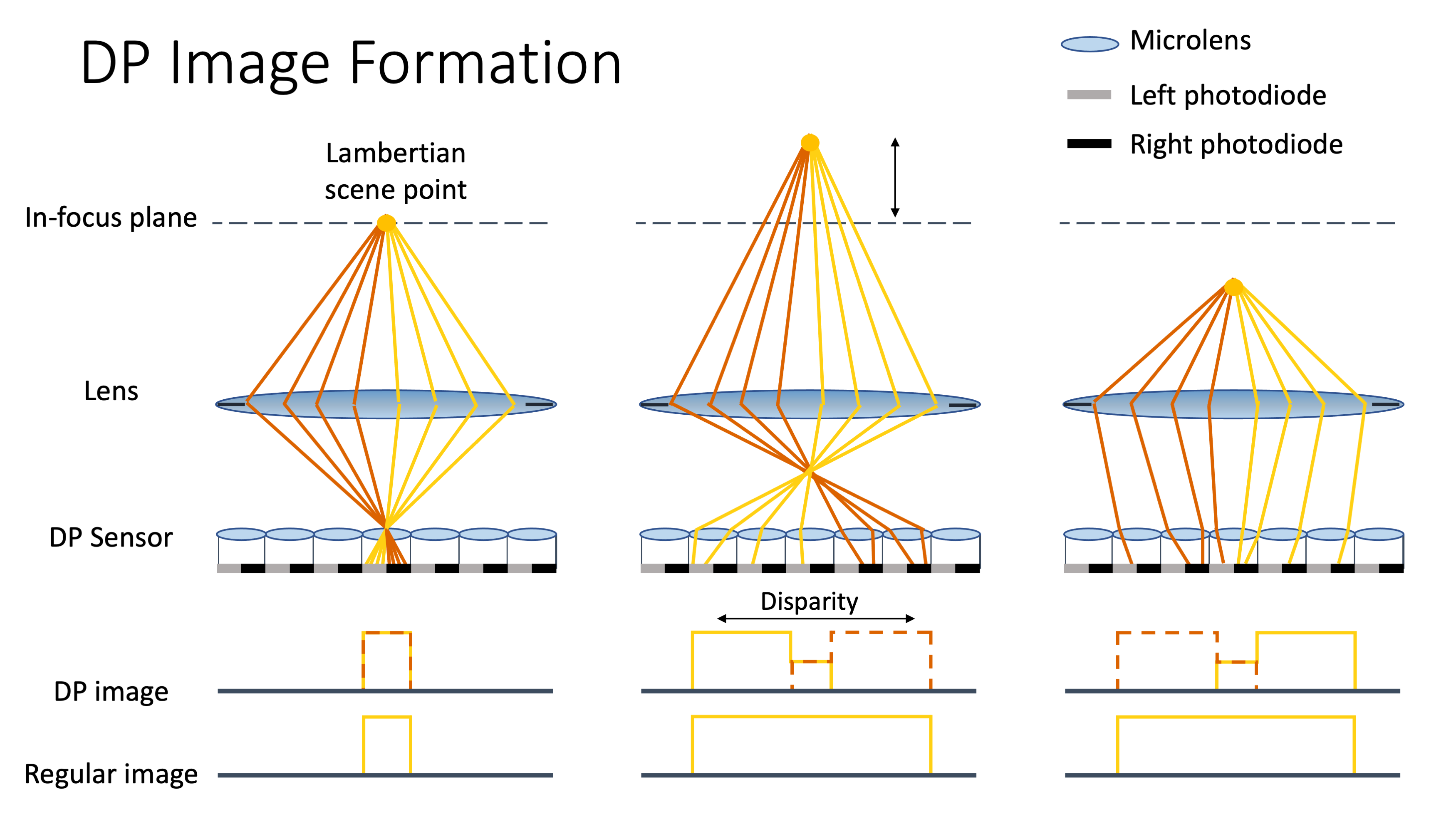
DP sensors were introduced in commercial cameras, such as DSLRs, mirrorless, and smartphones, to improve autofocus. Nowadays, they are becoming increasingly commonplace. Each pixel of a dual-pixel sensor is split in two parts, and thus the sensor simultaneously captures two sub images per exposure. We can think of it as a two-sample light field camera, or a stereo system with a tiny baseline.
To see why a dual-pixel sensor can help with depth from defocus, let’s consider its image formation model in a lens-based camera. This is very similar to the model for a regular sensor, except that each half pixel is integrating light from half the main lens aperture. An in-focus scene point produces identical left and right sub-images, whereas an out-of-focus point produces shifted sub-images. The shift, or disparity, depends on the distance of the scene point to the in-focus plane, and can be converted to depth in a calibrated system. Note that the sum of the two sub-images is the same as the image from a regular sensor. From a regular image alone, we cannot tell whether the point is in front of or behind the in-focus plane, whereas from the two sub-images, we can.
Our goal is to use the information available in a single dual-pixel image, and jointly recover the scene’s defocus map and all-in-focus image.

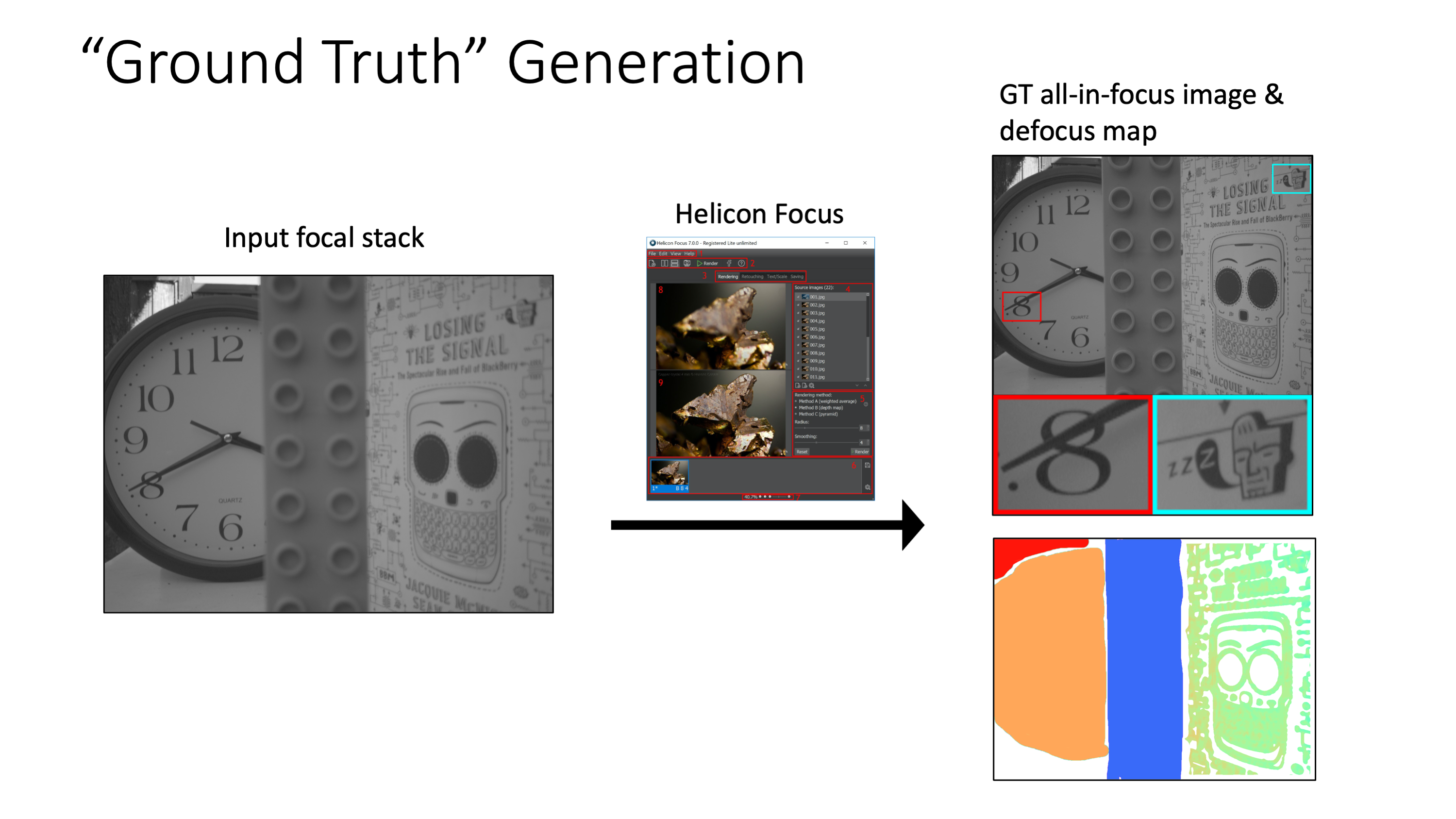
We test our method on a new dataset of 17 indoor and outdoor scenes we captured using a Google Pixel 4 camera. To generate ground truth, we use a commercial depth from focus software called Helicon Focus. This software computes all-in-focus images and defocus maps from input focal stacks. Note that we only use the generated ground truth for comparisons, and not for training.

We provide an interactive HTML viewer to facilitate comparisons across our full dataset. (Click on the image!)
For more details, please refer to our paper, supplementary material, poster, and video.
Shumian Xin, Neal Wadhwa, Tianfan Xue, Jonathan T. Barron, Pratul P. Srinivasan, Jiawen Chen, Ioannis Gkioulekas, and Rahul Garg. Defocus Map Estimation and Deblurring from a Single Dual-Pixel Image, ICCV 2021

Our code and data is available at the following Github repository.

We thank David Salesin and Samuel Hasinoff for helpful feedback. S.X. and I.G. were supported by NSF award 1730147 and a Sloan Research Fellowship.