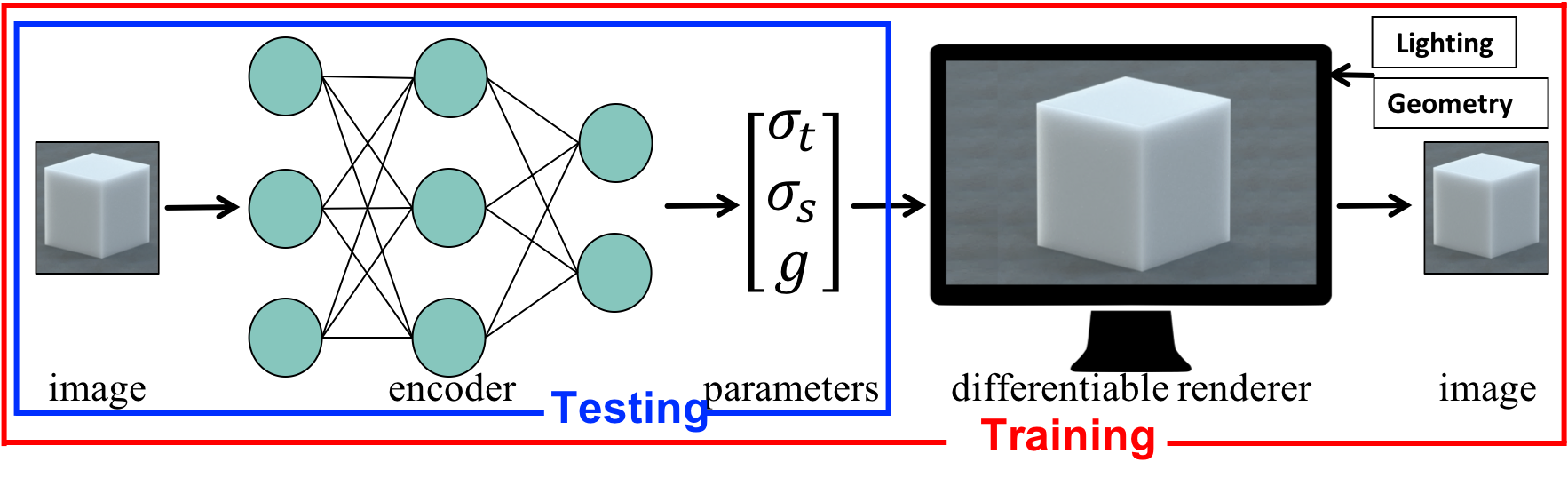
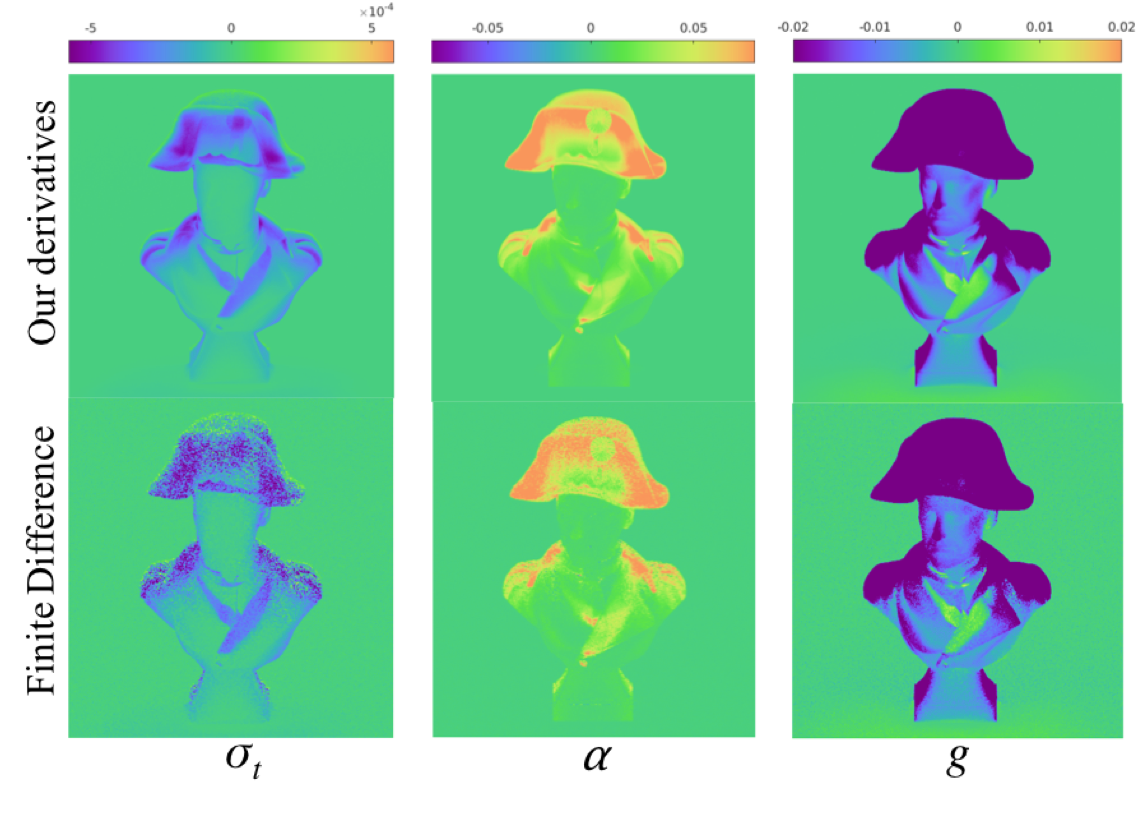
We propose a physics-aware learning pipeline that we term inverse transport networks (ITN), which aims to combine the computational efficiency of learning-based approaches with the generality of analysis by synthesis approaches for inverse scattering. We further tailor these neural networks towards inverse scattering, by taking into account results from the radiative transfer literature, characterizing the conditions under which different scattering materials can produce similar translucent appearance. We introduce ways for making our networks robust to these ambiguities, including the use of nonlinear material parameterizations, and weight maps emphasizing pixels where these ambiguities are weaker.