Abstract
We present an image formation model and optimization procedure that combines the advantages of neural radiance fields and structured light imaging. Existing depthsupervised neural models rely on depth sensors to accurately capture the scene’s geometry. However, the depth maps recovered by these sensors can be prone to error, or even fail outright. Instead of depending on the fidelity of processed depth maps from a structured light system, a more principled approach is to explicitly model the raw structured light images themselves. Our proposed approach enables the estimation of high-fidelity depth maps, including for objects with complex material properties (e.g., partially-transparent surfaces). Besides computing depth, the raw structured light images also confer other useful radiometric cues, which enable predicting surface normals and decomposing scene appearance in terms of a direct, indirect, and ambient component. We evaluate our framework quantitatively and qualitatively on a range of real and synthetic scenes, and decompose scenes into their constituent components for novel views.


Overview
Objective: Recover scene geometry and appearance components by optimizing a neural radiance field that models raw structured light images.
Structured light active sensors are common in consumer devices (e.g., iPhone, Intel RealSense), where a high-frequency pattern is projected onto the scene. Stereo-based depth processed from such sensors can be unreliable, especially in cases of complex materials and multi-path light transport.
Hence, we propose to model the physical image formation process of a structured light system under a known projection pattern. Such a neural volume rendering model enables high-fidelity geometry reconstruction in challenging scenarios, e.g., partially-transparent objects, global illumination, texture-less surfaces and sparse-views. Additionally, this method enables normals recovery and separation of direct, indirect, and ambient components for novel views.
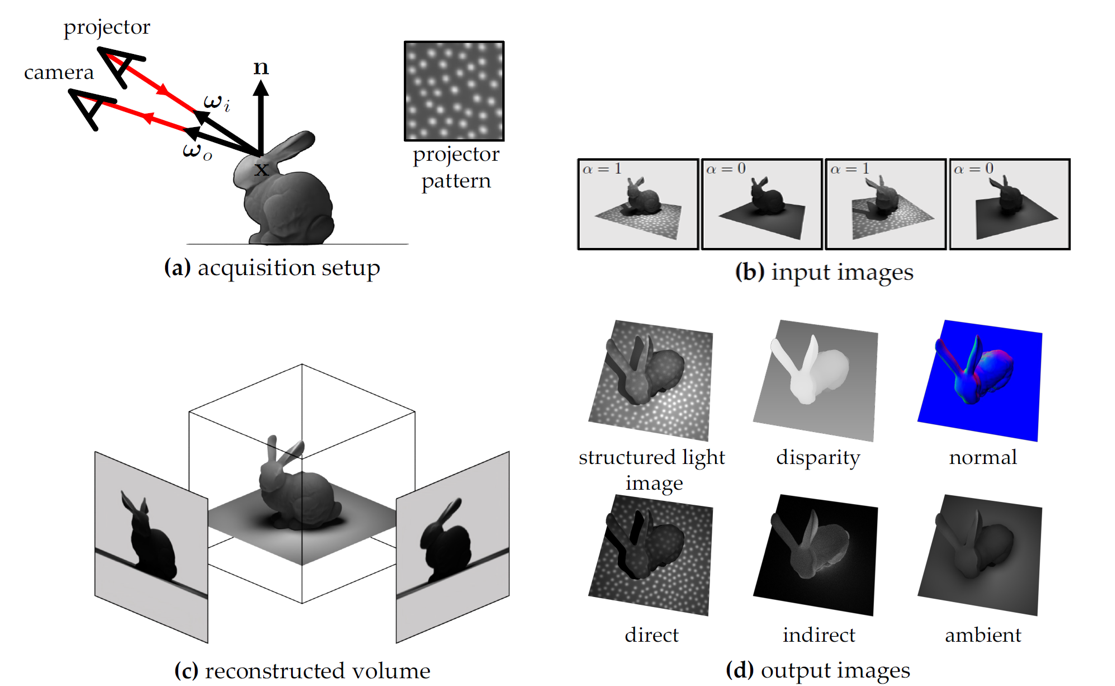
Illustrating the structured light reconstruction procedure: (a) A single camera and a projector illuminating the scene with a fixed projection pattern. (b) The projector strobes the illumination as the setup moves around the scene, producing an image sequence where the pattern alternates between on and off. (c) The proposed volume reconstruction problem recovers the appearance and shape representation of the scene. (d) The constituent components that make up appearance and shape can then be synthesized for novel views.
Full Scene Decomposition🔝
The proposed method can decompose scenes into a number of visual components, capturing different aspects of the scene's appearance (ambient, direct and indirect) and shape (disparity and normals).
Real Scene
Synthetic Scene
Seeing through Translucent Objects 🔝
In this example, we reconstruct scene geometry through a translucent mesh, positioned between the camera and the objects within the scene. When imaged under structured lighting, the partially-transparent mesh obscures the scene and effectively creates two copies of the structured light pattern: one copy representing light reflecting off of the mesh, and the other copy representing light reflecting off objects in the background. The RealSense completely fails to predict reasonable depth in such cases, and the depth cannot be used directly for training a NeRF. (In fact, depth-supervised NeRFs will not converge for such measurements.) In contrast, we show rendered ambient and disparity images using our approach, after digitally removing the mesh from the volume. Our method accurately reconstructs the geometry of the background, demonstrating our ability to "see through" meshes more reliably.
Translucent Mesh Scene
| Structured Light (example frame) | RealSense depth (example frame) |
 |  |
Note: The following are synthetized results after digitally removing mesh from volume reconstructed using structured lighting.
Predicting Normals🔝
A unique advantage of working with the raw structured light images (instead of the processed depth maps from a RealSense) is that these raw images provide shading cues that can be used to predict surface normals. When illuminating the scene with a light source (e.g., a projector), the incident radiance is scaled by the inner product between the surface normal and the lighting direction. By moving the light source to multiple different directions, the changes in shading can be used to more accurately predict surface normals.
Here, we showcase our framework's ability to recover scene appearance and shape using either (i) the dot illumination pattern (representing the structured light patterns used by RealSense), (ii) flood illumination, and (iii) no active illumination. Although all methods are capable of reconstructing ambient images relatively well, we observe that dot illumination patterns performs the best in terms of reconstructing depths and normals.
Sofa Scene
Reconstruction with dot illumination pattern
Reconstruction with flood illumination pattern
Reconstruction with no illumination pattern
Domino Scene
Reconstruction with dot illumination pattern
Reconstruction with flood illumination pattern
Reconstruction with no illumination pattern
Lego Scene
Reconstruction with dot illumination pattern
Reconstruction with flood illumination pattern
Reconstruction with no illumination pattern
Skateboard Scene
Reconstruction with dot illumination pattern
Reconstruction with flood illumination pattern
Reconstruction with no illumination pattern
Sparse-view Reconstruction🔝
Similar to depth-supervised NeRF methods, one advantage of incorporating structured light images is that it enables reconstructions from fewer views. We compare our model's performance with the following baseline approaches:
- NeRF: We train NeRF with the photometric loss on ambient images only.
- NeRF + Sparse: We train DS-NeRF, which includes a depth supervision loss using COLMAP's sparse point cloud.
- NeRF + Dense: Similar to DS-NeRF, we add a depth loss to NeRF, which uses the dense RealSense depth maps for supervision. We mask out the unresolved regions in the RealSense depth maps to avoid supervising with an unreliable signal.
- Structured Light: We train our proposed method with structured light measurements.
- Structured Light + Dense: We combine our approach with the RealSense depth supervision.
When the scene geometry can be reliably recovered using RealSense (such as in the examples shown below), we expect NeRF + dense, Structured lighting, and Structured lighting + Dense to have similar performance in recovering scene depth. However, methods that do not use the structured light images fundamentally cannot take advantage of shading cues for predicting normals, separate direct and indirect components, or handle scenes with more complex light transport properties (e.g., see mesh example).
Box Scene
2 View Reconstructions
4 View Reconstructions
8 View Reconstructions
Doll Scene
2 View Reconstructions
4 View Reconstructions
8 View Reconstructions
Sculpture Scene
2 View Reconstructions
Note: Reconstruction using structured light images is relatively poor in this 2-view case. This is because (i) there are multiple volumes that reproduce the input structured light images, and (ii) the two views are captured from very different perspectives. This ambiguity is resolved when using more views.